 最近接到一個比較罕見的需求,案主表示 Blogger 每篇文章設定的「搜尋說明」(可參考「Blogger 文章設定」→「六、搜尋說明」),在今年 5~6 月間的文章都不見了,詢問有沒有辦法可以救回。
最近接到一個比較罕見的需求,案主表示 Blogger 每篇文章設定的「搜尋說明」(可參考「Blogger 文章設定」→「六、搜尋說明」),在今年 5~6 月間的文章都不見了,詢問有沒有辦法可以救回。以前曾寫過「Blogger 網站消失」、「Blogger 文章誤刪」的案例,這次的案例看起來比較輕微一些,至少文章還在,只是某些資訊消失了。
由於之前的案例發生在 4~5 年前,當時還不知道「Wayback Machine」(網站時光機)這個網路服務,否則的話,這個超強的網路服務有機會可以救回所有不見的網頁內容,可以說是目前最強的網頁救援武器。
當然,建立網頁備份的觀念才是終極解決方案,但是網頁會急著需要救援一定都是還沒想到要備份之下發生的憾事,那麼本篇就來看看如何操作這個工具。
一、網站時光機 Wayback Machine
1. 簡介
可參考 Wiki 的介紹「網站時光機」,這是一個非營利組織「網際網路檔案館」提供的服務,創辦人希望為網際網路提供「普遍取得所有知識」的途徑。
構想十分偉大,因為無償需要用來儲存的伺服器空間非常巨大,該網站進入後就有個 DONATE 按鈕,WFU 因為靠這個網站救回一些重要資料,也曾贊助過表達一點心意。
2. 教學文章參考
「免費資源網路社群」曾寫過這篇「Wayback Machine 網站時光機帶你重溫那些年」,除了簡單介紹這個網站,也提供了「網頁備份」的操作步驟教學心得。
3. 優缺點說明
有的站長或許習慣使用 Google 搜尋結果的「庫存頁面」功能來救援網頁,不過「庫存頁面」能做到的其實有限,否則 WFU 也不會對 Wayback Machine 心存感激了。Google 庫存頁面的優缺點在於:
- 索引速度會比 Wayback Machine 快
- 但只有一個版本,所以只會保留最新庫存頁面狀態
- 萬一要救援的網頁內容,最新狀態已經被 Google 索引,也就是錯誤的頁面內容已經被索引,那麼就看不到以前的正確頁面內容了
- 所以救援網頁要靠「庫存頁面」的話,手腳必須比 Google 還快才行
而 Wayback Machine 雖然是目前最強的工具,也不代表他可以 100% 救回所有頁面,因為:
- NGO 資源畢竟有限,不會保存世界上所有網頁
- 越熱門的網頁,Wayback Machine 的更新會越頻繁、保留的版本數也越多
- 不熱門的網頁,說不定只會有一個版本
- 也可能某些低流量的網頁,完全不會被 Wayback Machine 收錄
二、如何救回完整網頁內容
首先拿一篇文章當範例,說明如何利用 Wayback Machine 找回文章內容。我從 10 月的文章一路測試到 7 月底,終於找到三個月前有被收錄的文章,代表 Wayback Machine 索引速度很慢。
1. 取得網頁快取內容
範例文章為這篇「Adsense 申請 + 廣告無法顯示的各種疑難雜症整理」,在 Wayback Machine 首頁輸入該篇網址:
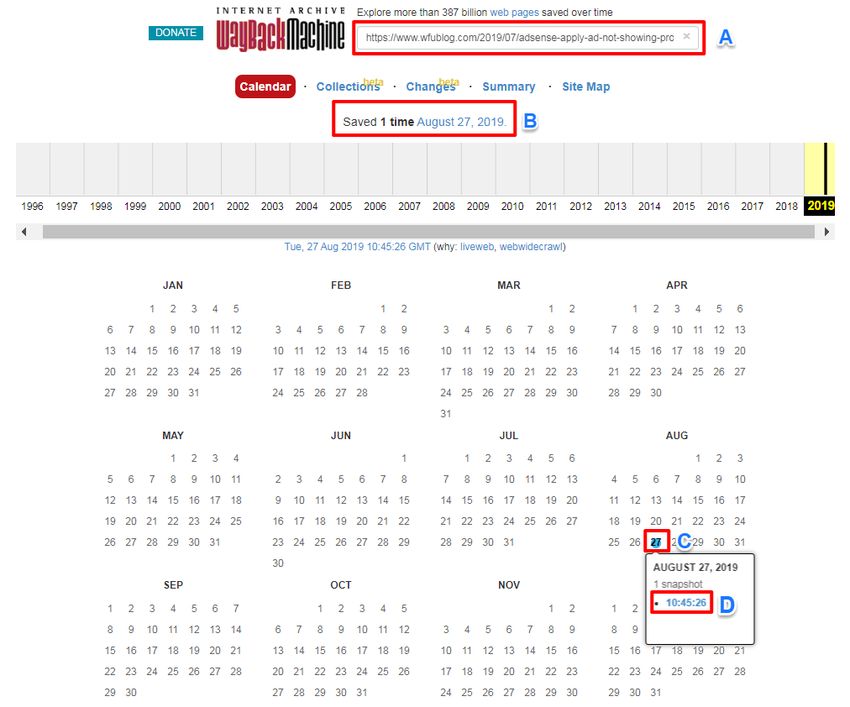
- A:輸入要救回的網址
- B:如果有被收錄的話,記下這裡的收錄日期
- C:在月曆找到對應的日期,滑鼠移到日期上
- D:會出現收錄的時間點,點擊這個連結,會出現快取頁面
2. 取得網頁內容
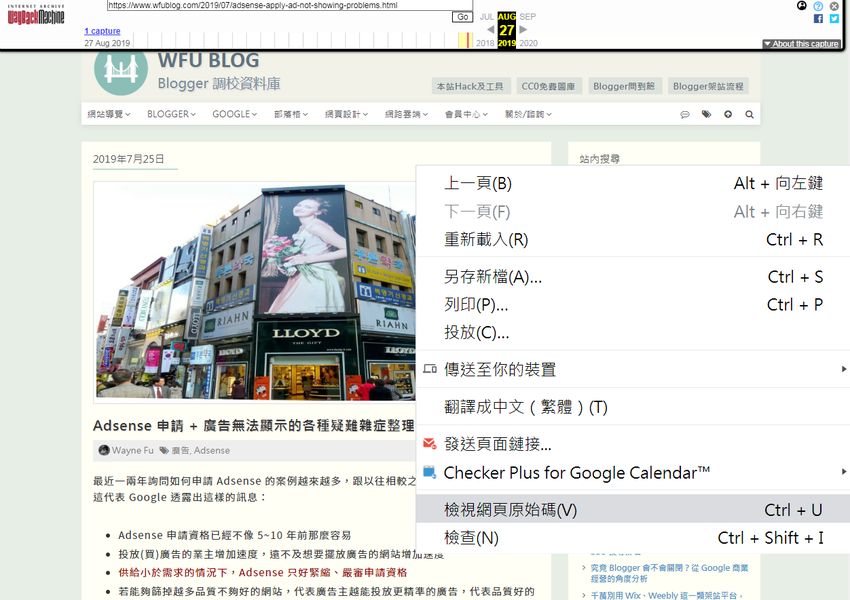
上圖是快取頁面,如果只是要取得純文字,那麼直接從頁面上選取、複製即可。
如果要取得 HTML 碼的話,有兩種方式:
- 按滑鼠右鍵 → 檢視網頁原始碼 → 找到文章區塊的段落來複製
- 使用瀏覽器,例如「Chrome 開發人員工具」,因為可以收合 HTML 內容,處理比較方便
3. 調整 HTML 內容
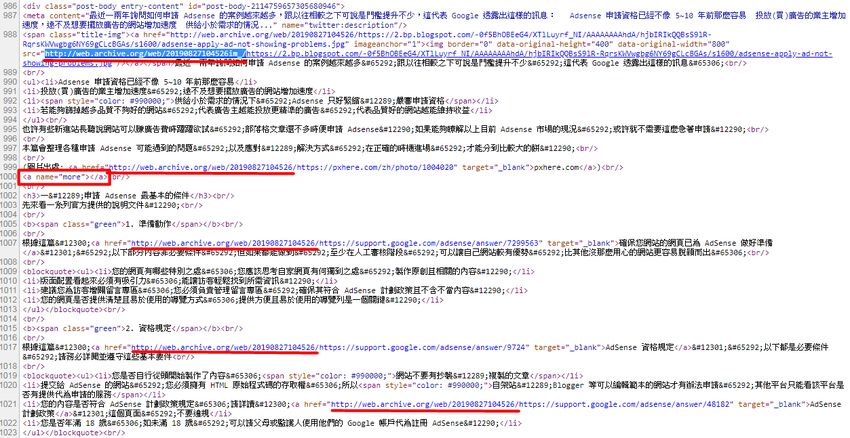
並不是拿到快取頁面的 HTML 就能直接拿來用,因為裡面的連結全部被加上特定的字串,必須一一去除。請見上圖:
- 所有紅色底線的地方,可看出圖片網址或連結網址,前面都有 "http://web.archive.org/web/xxxxxxxxx"這樣的字串
- 可將內容複製到文書處理軟體,用全部取代的方式,一一去除這些字串,留下原始的網址連結。
- 紅框處可看到
<a name="more"></a> ,原本是部落格文章「繼續閱讀」的程式碼,但被轉換成這樣的 HTML - 要把紅框處字串改成
<!--more--> 才能正確變成繼續閱讀標記
主要修改的地方有這些,改完才能將這些 HTML 碼貼回網站。
三、搭配 Feedly 使用
如果你的網站是部落格,那麼還有另一個救命仙丹「Feedly RSS 閱讀器」,只要有人訂閱過網站,Feedly 就會自動保留文章備份內容。
但 Feedly 不一定有 Wayback Machine 好用,以下是優缺點:
- Feedly 大致是 2013 年左右接下 Google Reader 的位置
- 在那個時間點之前的文章,伺服器多半沒有備份資料
- 所以 Feedly 能保存的資料比較少
- Feedly 網頁的內容會加料,不容易直接複製 HTML 碼
- 只適合救回文字及(圖片)連結
因為 Wayback Machine 有可能某些網頁沒有收錄快取,那麼 Feedly 可能就會是那些頁面的救星。
四、如何救回 Blogger 搜尋說明
回到開頭的案件,Blogger 每篇文章的「搜尋說明」,在頁面上是看不到這些內容的,那麼要如何找到「搜尋說明」呢?
在 Blogger 範本中,跟搜尋說明有關的 Blogger 語法是
例如前面的範例網頁,網頁原始碼畫面如下:

- 以這個案例來看,「搜尋說明」的相關語法出現在字串
og:description 附近 - 上圖紅框標起來的字串,正是在
og:description 同一行的位置 - 那麼這些字串就是當初所設定的「搜尋說明」字串
五、補充說明
從本篇的案例來看,如果不是自己手誤、不小心刪除文章的相關資訊,那麼很可能是 Blogger 伺服器的失誤,導致部分資訊消失。這件事告訴我們不可完全信任網路服務,站長們有必要自己執行備份的任務。
經由本篇說明,我們可以了解到 Wayback Machine + Feedly 有辦法救回多數的頁面內容,但不一定是 100%。想要萬無一失的話,必須儘早養成備份網頁的習慣,而且是同步異地備份。
可參考「自動備份 Blogger 文章」,同時採取多個自動備份的方案,就比較不用擔心任何天災人禍了。
更多「網站工具」相關文章: