 之前曾記錄使用 Google Apps Script(簡稱 GAS) 爬網頁資料,「解析 HTML 及操作 DOM 的技巧」,主要利用 GAS 的 XmlService 這個官方函數。
之前曾記錄使用 Google Apps Script(簡稱 GAS) 爬網頁資料,「解析 HTML 及操作 DOM 的技巧」,主要利用 GAS 的 XmlService 這個官方函數。而最近爬 XML 頁面時,發現之前記錄的心得不敷使用,沒想到 XML 架構有點難以理解。因此花了點時間解決問題,也另外記錄一下心得。
(圖片出處: pxhere.com)
一、GAS 標準範例
首先看一下官方提供的標準範例,來自官網「XML Service」:
function parseXml() {
var url = 'https://gsuite-developers.googleblog.com/atom.xml';
var xml = UrlFetchApp.fetch(url).getContentText();
var document = XmlService.parse(xml);
var root = document.getRootElement();
var atom = XmlService.getNamespace('http://www.w3.org/2005/Atom');
var entries = root.getChildren('entry', atom);
for (var i = 0; i < entries.length; i++) {
var title = entries[i].getChild('title', atom).getText();
var categoryElements = entries[i].getChildren('category', atom);
var labels = [];
for (var j = 0; j < categoryElements.length; j++) {
labels.push(categoryElements[j].getAttribute('term').getValue());
}
Logger.log('%s (%s)', title, labels.join(', '));
}
}以上需要注意的是紅字那兩行,getNamespace 是取得「命名空間」(namespace)之意,概念說明可參考 Wiki「XML命名空間」。
不是每個 HTML 頁面都有設定命名空間,同樣也不是每個 XML 頁面都有命名空間。之前解析 HTML 網頁時,剛好沒處理命名空間同樣可以正常執行,但這次解析 XML 頁面就踢到鐵板,所以如果 XML 頁面無法正常解析時,就必須注意紅字內容,檢查該頁面是否設定了命名空間:
- 先用 getNamespace 取得該 XML 頁面的命名空間
- 接著取得頁面任何元素,例如使用 getChildren 時,都需要加入命名空間的參數
- 否則可能什麼東西都取不出來
二、YouTube 播放清單 feed 頁面
直接以實際範例說明比較容易理解,例如下面是 YouTube 提供的影片播放清單 RSS Feed,公視「有話好說」XML 頁面:
https://www.youtube.com/feeds/videos.xml?playlist_id=UUgxXuXHJ4VwovSTvDiWlzZQ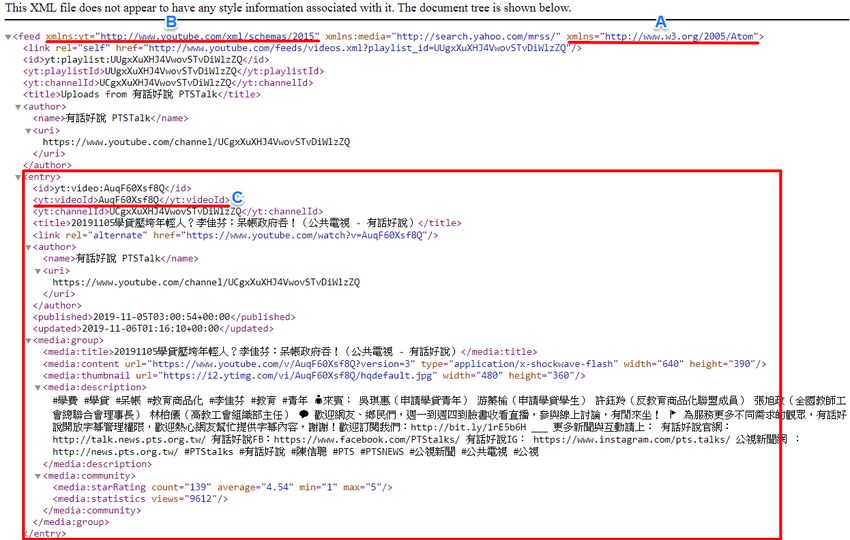
從這個頁面可以爬到的資料相當多,例如影片 id、標題、作者資訊等等:
- A:紅色底線這裡,就是這個 XML 頁面的 namespace 命名空間
- B:此處的紅色底線是另一個困難的概念,這裡是 yt 這個命名空間
- C:如果要從此處的 videoId 元素取得影片 id 字串,請注意到有個前綴字串 yt,這就是該元素命名空間
以上就是使用 XmlService 會卡關的地方,以下來看範例程式碼。
三、爬取 XML 頁面範例程式碼
同樣以公視「有話好說」的 RSS Feed 當範例,嘗試以 GAS 來爬取 XML 頁面內容,取得每個影片的 id、標題:
(function() {
// 取得清單 feed 內容, 解析 xml 格式
var xmlUrl = "https://www.youtube.com/feeds/videos.xml?playlist_id=UUgxXuXHJ4VwovSTvDiWlzZQ",
xml = UrlFetchApp.fetch(xmlUrl).getContentText(),
doc = XmlService.parse(xml),
root = doc.getRootElement(),
atom = XmlService.getNamespace('http://www.w3.org/2005/Atom'), // 這個 feed 一定要有 namespace 才能讀取
yt = XmlService.getNamespace('http://www.youtube.com/xml/schemas/2015'), // 有 prefix 前綴 yt 一定要有 namespace 才能讀取
entries = root.getChildren("entry", atom), // 一定要加上 atom namespace 才能取得
i, videoId, programTitle;
// loop 所有影片
for (i in entries) {
// 取得影片 id, 影片標題
videoId = entries[i].getChildText("videoId", yt); // 一定要加上 yt namespace 才能取得
programTitle = entries[i].getChildText("title", atom); // 一定要加上 atom namespace 才能取得
Logger.log("影片 id = "+videoId);
Logger.log("影片標題 = "+programTitle);
}
})();所有注意事項請直接看註解字串,並參照前面「二、YouTube 播放清單 feed 頁面」的說明即可理解。
參照此範例後,要取得此頁面其他欄位的資料,按相同邏輯加入參數即可抓到。
更多 相關文章: